



MongoDB storage engine: MMAP or WiredTiger?
OCT 18, 2015
Pluggable Storage Engines
As MongoDB grows in popularity, developers are building new and awesome things in many different use cases. With this, a one size fits all solution is becoming even more difficult to find. To allow new kinds of optimizations, MongoDB 3.0 was shipped with the concept of pluggable storage engines. This allows the community to create new engines to solve and optimize specific problems.
A storage engine is the component that handles how memory is controlled and how data is persisted and retrieved from the storage device. You can change this component without needing to change your application code since this layer is well separated. It doesn't affect how data is distributed between different Mongo servers and doesn't affect which methods the Mongo API exposes.
So far, we have two stable engines: MMAPv1 (the old one) and WiredTiger (the shinning new one). MongoDB 3.0 ships with MMAPv1 as the default engine to avoid impacts in current solutions, but WiredTiger has many new interesting things that you need to know.
Besides those two, there are many other engines that are under development, in an experimental phase or done but simply not yet popular. I'm writing this post in 2015. If you are really willing to change your storage engine, you may search more about your options. Below follows a brief intro about the current options:
In-memory engine: it's not ready yet, but may be used in the future for cache services. It's also interesting for unit testing.
mongo-rocks: is a key-value engine created as a integration layer for Facebook's RocksDB.
Fusion-io: this storage engine was created by SanDisk and makes it possible to bypass the operating system file system layer and write directly to the storage device.
TokuMX: a storage engine created by Percona that uses fractal tree indexes instead of B-tree indexes.
/dev/null: Is a storage engine where everything that you write is discarded and all your reads return empty results. It sounds stupid, but can be useful in some scenarios. For example, when you want to find performance bottlenecks in your app that are not related with your DB.
MMAP
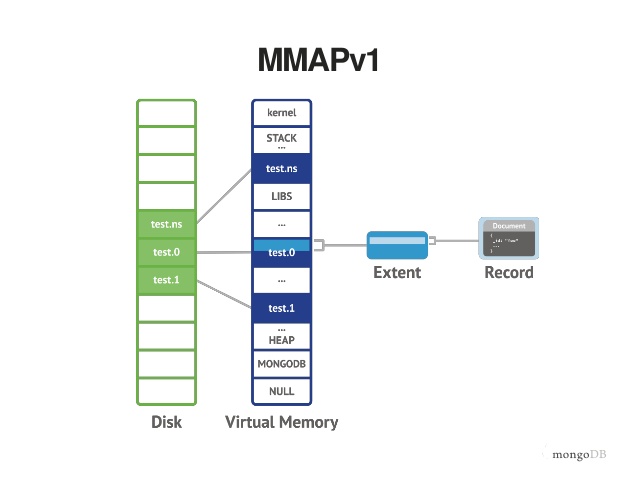
MMAPv1 is named after the mmap() Linux command that maps files to the virtual memory and allows page optimization for some use cases. For example, when you have a large file but you need to read just specific parts of it, mmap() is much faster then a read() call that would bring the entire file to memory.
MMAPv1 has collection-level locking but hasn't document-level locking. The problem is that you can't have two write calls being processed in parallel for the same collection. So, one writer must wait for the other to finish. This collection-locking is necessary because one MMAP index can reference multiples documents and if those docs could be updated simultaneously, the index would be inconsistent.
WiredTiger
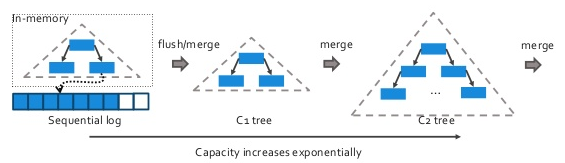
MMAP uses B-trees to store indexes and WiredTiger uses B-trees by default but also supports LSM trees (image above was adapted from here).
LSM trees provides an advantage when you need to write huge workloads of random inserts, when data is much larger then the cache and when background maintenance overhead is acceptable.
In WiredTiger, there is no in-place updates. If an element of a document needs to be updated, a entire new document will be written to disk while the old document will be removed.
WiredTiger offers document-level concurrency. That means that it assumes that two write operations will not affect the same document at the same time and, if it does affect, one operation will rewind and will be executed again later. That's a great performance boost if rewinds are rare.
Another characteristic is that WiredTiger offers compression of data and indexes in the file system. It supports Snappy and zLib algorithms where Snappy, the default, is less CPU-intensive but have a lower compression rate than zLib.
Benchmarks
When WiredTiger for MongoDB was launched, it was advertised as able to perform 7x-10x better in write operations and to compress up to 80% of the file system. Yeah, that's a huge gain. Bellow follows more benchmark data collected from here, here and here.
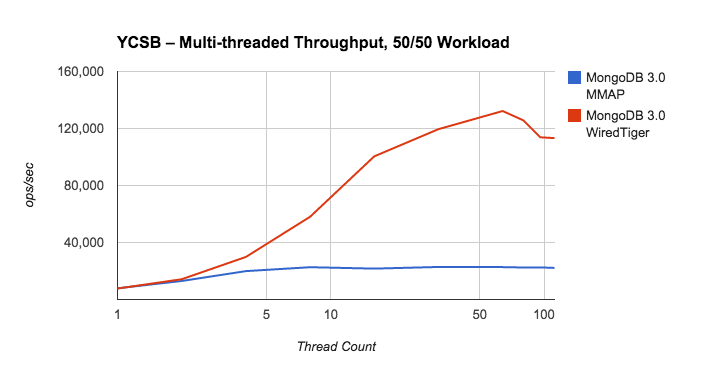
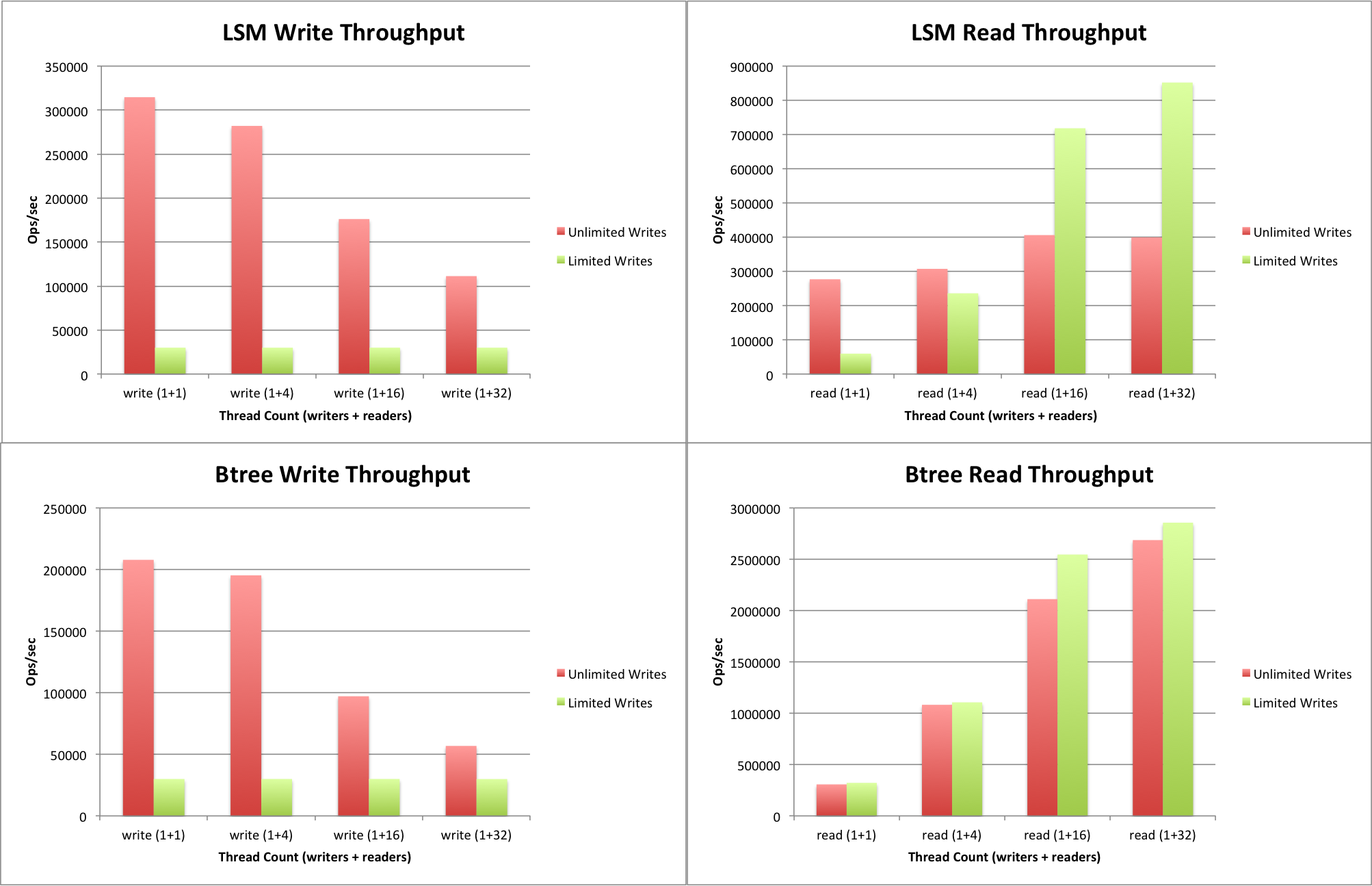

Conclusion
TL;DR: if your app is read-heavy, use MMAP. If its write-heavy, use WiredTiger.
An interesting side note is that your solution may have a mixed replica set members where you can have one node configured with WiredTiger to receive a massive load of data and another node with MMAP to be used by analytical tools. As replication automatically migrates data between primary and secondary replica set members, independent of their underlying storage formats, you can avoid using complex ETL tools.
Just one note: if your DB file was created with MMAP, you'll need to create a new database if you want the node to run with WiredTiger, since it can't open a MMAP DB file. The inverse is also true. Since they use different ways to store the data, you can't reuse the same files, but in a replica set, data is exchanged without problems.