



"Please, try again..." (Retry Pattern in Node)
APR 09, 2016
Retry Pattern
Problem - what are we trying to solve?
Networks are unreliable, connections may be dropped or timeout, databases can be overloaded and become unable to process your request. There are many reasons for a valid request to be discarded due to external factors. In those cases, we may try sending the same request again. The question is when we have to retry and when we have to accept the failure. The objective here is to achieve fault-tolerance whenever possible to build resilient applications.
This approach is specially important when we are developing windows services, jobs, scheduled events, daemons, etc. If the background process runs one time per day and it is not fault tolerant, it may create bad side effects.
Context - when should we Retry?
Retrying is a good approach when you know that the error is transient. Retrying blindly may only yield the same error and be a waste of computer resources.
We should retry when:
- When the external service returns the following HTTP error codes: HTTP 408 (Request Timeout), HTTP 429 (Too Many Requests - try after a longer period), HTTP 503 (Service Unavailable) or HTTP 504 (Gateway Timeout).
- When the external service returns the HTTP 500 error code but we have a pretty good guess that it could be caused by a unhandled exception created by a transient problem: if the service relies on other services and may not be so fault-tolerant as ours.
- When the database or another backend resource reports timeouts or other known error type that suggests a transient failure.
We shouldn't retry when:
- When the request was done by an user: simply return an error message like "An error has occurred, please try again later". We can avoid dead retries by asking for the user to decide what is the best way to handle the problem. Usually, the user will prefer to see a fast response saying that an error has occurred than having to wait a few minutes with the risk of seeing the same error message.
- When we don't have any idea about what caused the error: if the error is caused by a programming bug, you shouldn't try repeatedly.
- When the request is not idempotent*: if the request is "select something from tableX" or "update X to Y", we can try again without worrying about side effects. However, if the request is "delete the first report" or "insert a new order", we should not retry to avoid deleting wrong things or duplicating content.
* Idempotency: an idempotent method is the one that can be called many times without different outcomes. More here.
Issues and Considerations
Regarding how many times you need to retry is a question answerable only knowing the specific case. Usually, we would retry only three times waiting between 30 or 60 seconds per request, but this number can be increased if the execution of the request is critical for the operation. Just avoid retrying infinitely because it will be probably just a waste of resources.
Other things to consider:
- It may be better for some noncritical operations to fail fast rather than retry several times and impact the throughput of the application.
- A highly aggressive retry policy with minimal delay between attempts, and a large number of retries, could further degrade a busy service that is running close to or at capacity.
- Test the retry code! You should avoid infinite loops and non-idempotent retries.
- Log all retry actions. If it is frequently used, probably there is another hidden problem yet to me identified.
Solution - how can I Retry?
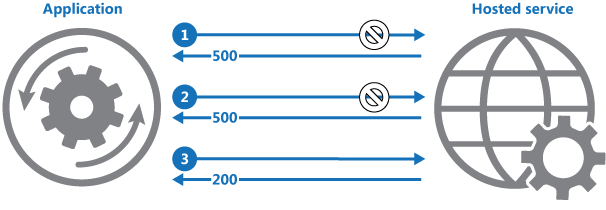
The retry logic is quite simple: you just need to loop X times, waiting a few seconds between each loop and retry if you know that the error is transient. If you succeed or the limit is achieved, you abort the loop.
while (true) {
try {
// execute the task and break the loop if it succeeds
} catch (e) {
// if (e instanceof CommunicationError && attempts < limit)
// try again after a few seconds
}
}
However, implementing this in Node considering async operations is a little bit more complex. So, why don't we use a well tested module? I suggest retry that is specialized in this task or the almighty async module that has also a retry feature.
For this example, I'll pick the retry module.
Installation
> npm install retry
Testing
retry uses an exponential backoff strategy to calculate how much time each retry attempt must wait. It's a very clever solution. You can read more about in the official docs.
Below follows an example using this module:
var retry = require('retry');
// configuration
var operation = retry.operation({
retries: 2, // try 1 time and retry 2 times if needed, total = 3
minTimeout: 10 * 1000, // the number of milliseconds before starting the first retry
maxTimeout: 30 * 1000 // the maximum number of milliseconds between two retries
});
// define a custom error
function CommunicationError() {}
// define a function that represents our unreliable task
var task = function(input, callback) {
Math.random() > 0.7
? callback(null, 'ok') // success in 30% of the cases
: callback(new CommunicationError()); // error in 70% of the cases
}
// define a function that wraps our unreliable task into a fault tolerant task
function faultTolerantTask(input, callback) {
operation.attempt(function(currentAttempt) {
task(input, function(err, result) {
console.log('Current attempt: ' + currentAttempt);
if (err instanceof CommunicationError // test if is a transient error - optional
&& operation.retry(err)) { // test if is retriable and retry if needed
return;
}
callback(err ? operation.mainError() : null, result);
});
});
}
// test
faultTolerantTask('some input', function(err, result) {
console.log(err, result);
});
Read more
This post was inspired by this MSDN article (with C# examples).